
AWS 공부를 하면서 읽기 전용 데이터 베이스라는 것을 알게 되었고, 실습을 하면서 Django 프로젝트에 적용시킨 방법에 대해 정리해보려 한다. 아래의 내용은 AWS를 이용하여 읽기 전용 데이터베이스를 구현한 내용이다.
[AWS] RDS 읽기 복제본 - 읽기 트래픽 분산
RDS 읽기 전용 복제본을 생성하고 서버에 트래픽을 분산할 수 있도록 해보자. 읽기 전용 복제본 읽기 전용 복제본 생성을 위해 RDS 콘솔의 데이터베이스로 이동, Actions을 보면 읽기 전용 복제본
jongseoung.tistory.com
데이터 베이스 설정
Settings.py 변경
Django의 여러 데이터베이스를 사용하기 위해서 settings.py의 DATABASES 설정을 변경하여준다. default는 쓰기 전용, replica는 읽기 전용으로 설정하였다.
DATABASE_ROUTERS는 라우터 설정에서 작성한 코드를 등록하는 부분이다.
DATABASE_ROUTERS = ['core.db_router.PrimaryReplicaRouter']
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'write_db',
'USER': 'write_user',
'PASSWORD': 'write_password',
'HOST': 'write_db_host',
'PORT': '5432',
},
'replica': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'read_db',
'USER': 'read_user',
'PASSWORD': 'read_password',
'HOST': 'read_db_host',
'PORT': '5432',
},
}
라우터 설정
데이터베이스 라우터를 통해 특정 동작에 대해, 어떤 데이터 베이스를 사용할 것인지 정의해 주어야한다. 아래처럼 읽기 작업에 대해서는 replica를 쓰기 작업에 대해서는 default를 사용하도록 설정해 주었다.
또한, 관계 허용 여부를 default, replica를 확인하고 있으면 True로 설정해 주었다.
Django가 관계형 필드를 조회할 때, 관계를 막지 않기 위해서 allow_relation에서 True를 반환하는 것이다. 예를 들어, User와 Profile이 관계를 맺고 있는 경우, django는 두 모델의 인스턴스가 서로 다른 데이터 베이스에 있더라도 그 관계를 사용할 수 있도록 해줘야 하기 때문이다.
즉, GET 요청이라고 무조건 replica만 사용하는 것은 아니다!! -> 이 내용을 몰라서 GET 요청에서 자꾸 default를 왜 사용하지? 내가 뭔가 잘못한 건가 라는 생각을 가지고 한참을 고민을 했다.
class PrimaryReplicaRouter:
"""
A router to control all database operations on models for
default/replica (write/read) setup.
"""
def db_for_read(self, model, **hints):
"""
읽기 전용 데이터베이스로 읽기 작업을 전달
"""
return 'replica'
def db_for_write(self, model, **hints):
"""
기본 데이터베이스로 쓰기 작업을 전달
"""
return 'default'
def allow_relation(self, obj1, obj2, **hints):
"""
기본 데이터베이스와 읽기 전용 데이터베이스 간의 관계를 허용합니다.
"""
db_list = ('default', 'replica')
if obj1._state.db in db_list and obj2._state.db in db_list:
return True
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"""
모든 마이그레이션 작업은 기본 데이터베이스로 전달
"""
return True
테스트
이제 로깅 설정을 통해, 현재 데이터베이스에 대해 어떤 데이터 베이스가 동작 중 인지 확인해 보자.
Settings.py 작성
아래는 로깅 설정으로 Django의 애플리케이션에서 db_logger라는 로거가 DEBUG 이상의 로그 메시지를 남길 때, 해당 로그를 db_url.log 파일에 기록하는 설정이다. 로그는 시간, 로그 수준, 로거 이름, 로그 메시지로 포맷되어 출력된다.
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'verbose': {
'format': '{asctime} {levelname} {name}: \n {message}',
'style': '{',
},
},
'handlers': {
'file': {
'level': 'DEBUG',
'class': 'logging.FileHandler',
'filename': os.path.join(BASE_DIR, 'db_url.log'),
'formatter': 'verbose',
},
},
'loggers': {
'db_logger': {
'handlers': ['file'],
'level': 'DEBUG',
'propagate': False,
},
},
}Logging.py 작성
Logging.py에서 log_db 함수에서 하는 일은 간단하다, 현재 사용 중인 데이터 베이스에서 HOST 값을 가지고 와서 alias와 함께 로거를 남기도록 작성하였다. 여기서 alias는 앞서 정의한 'default'와 'replica'를 의미한다.
import logging
from django.db import connections
logger = logging.getLogger('db_logger')
def log_db():
for alias, connection in connections.databases.items():
host = connection.get('HOST', 'localhost')
logger.info(f"Using database alias: {alias} - Host: {host}")
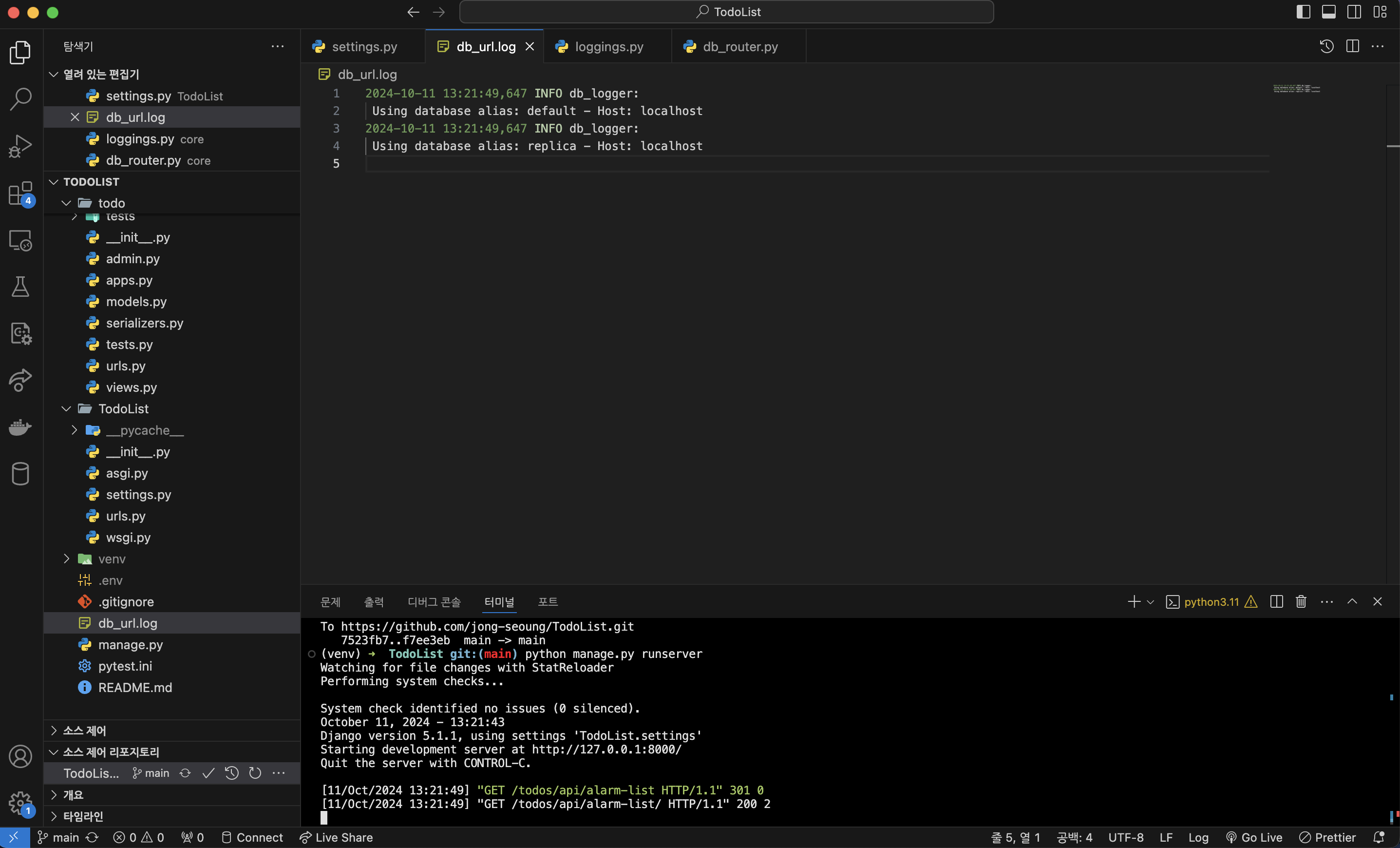
확인
이제 어떤 데이터 베이스를 사용하는지 확인하고 싶은 View에 log_db()를 작성하고, api를 호출해서 log 파일에 정상적으로 출력이 되는지 확인해 보면 된다.

로컬 환경이어서 읽기 전용 데이터 베이스를 굳이 만들진 않고, 데이터베이스는 같고 alias만 다르게 해서 테스트하였다.
'Django > DRF' 카테고리의 다른 글
| [DRF] 쿼리 성능 향상 (Feat. ORM 최적화 기법) (0) | 2024.10.29 |
|---|---|
| [Django] 테스트 : pytest-django, factory-boy, facker (2) | 2024.10.21 |
| [Django] 랜덤 객체를 가지고 오는 방법 (1) | 2024.09.13 |
| [DRF] Django REST framework의 권한 관리 (0) | 2024.09.12 |
| [Django] 캐시 API (0) | 2024.08.21 |